数据库
数据库集成功能仅在 Crawlab 专业版 中可用。
默认情况下,Crawlab 将收集的数据保存到默认数据库(MongoDB)。然而,Crawlab 的目标是成为一个多功能的网络爬虫管理平台, 这意味着它可以用于管理各种用途的爬虫。因此,它被设计为灵活的,并且可以轻松集成到主流数据库中,以便您可以将抓取的数据存储到您选择的数据库中。
Crawlab 数据库模块类似于一些数据库管理工具,如 DBeaver 或 DataGrip。
支持的数据库
Crawlab 目前支持以下数据库:
我们正在努力添加更多数据库支持,包括但不限于:
数据库管理
Crawlab 提供了一个集中的数据库管理界面,在这里您可以管理您的数据库和数据集合。
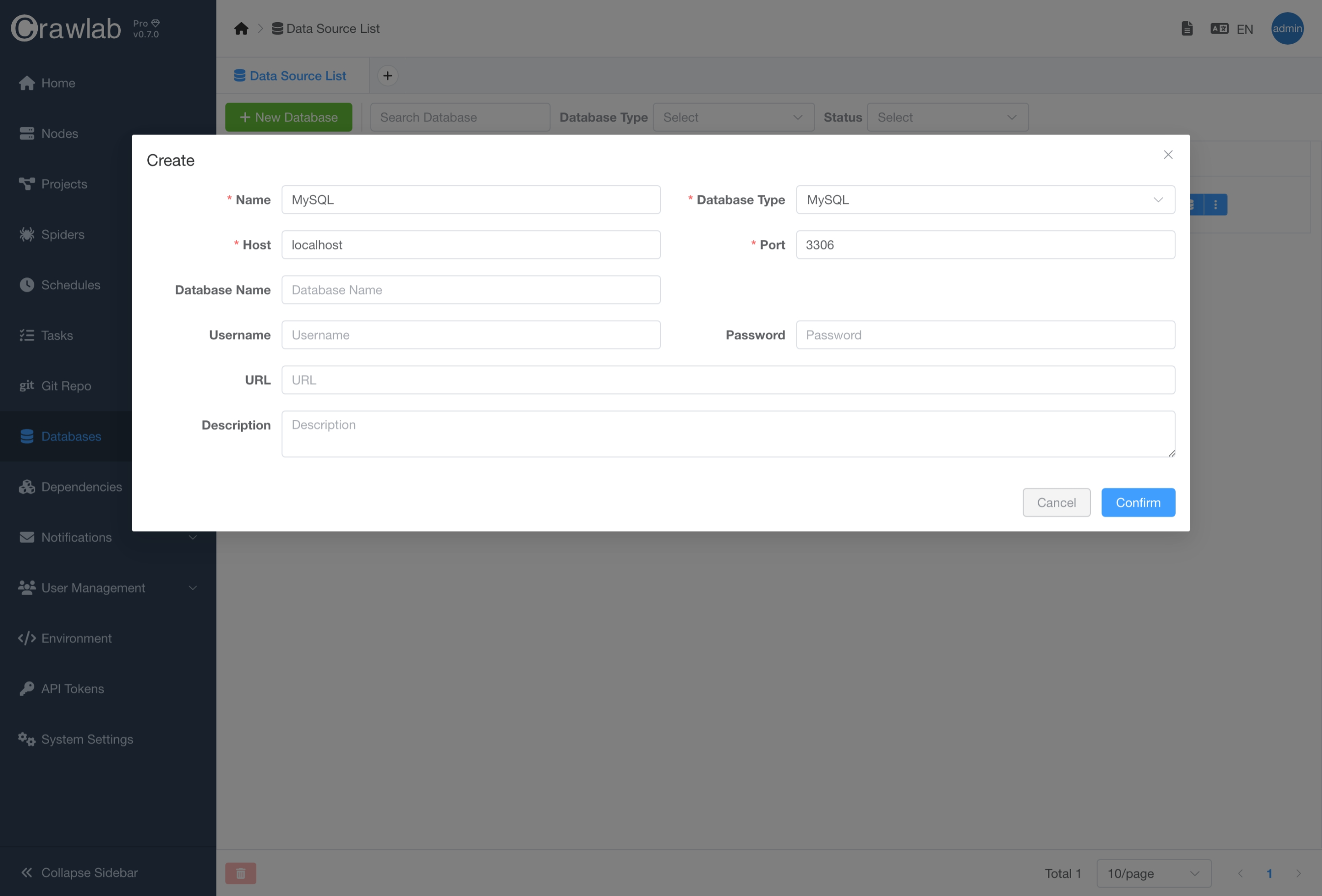
创建数据库
您可以通过点击数据库管理界面中的 新建数据库 按钮并输入数据库连接信息来创建新数据库。
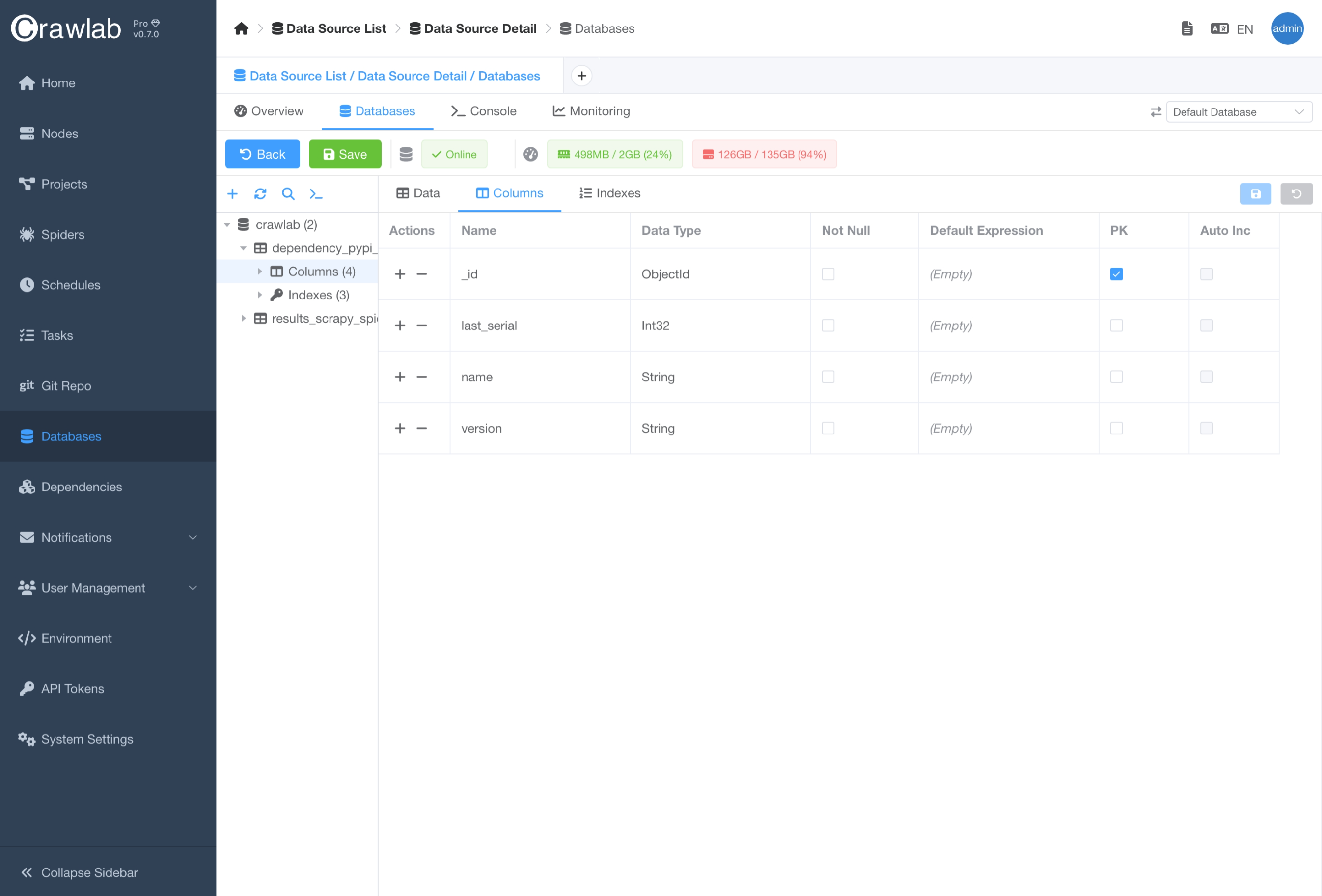
更新数据库模式
您可以在 数据库 详细页面的 数据库 标签页中像添加、更新或删除表一样更改数据库模式。
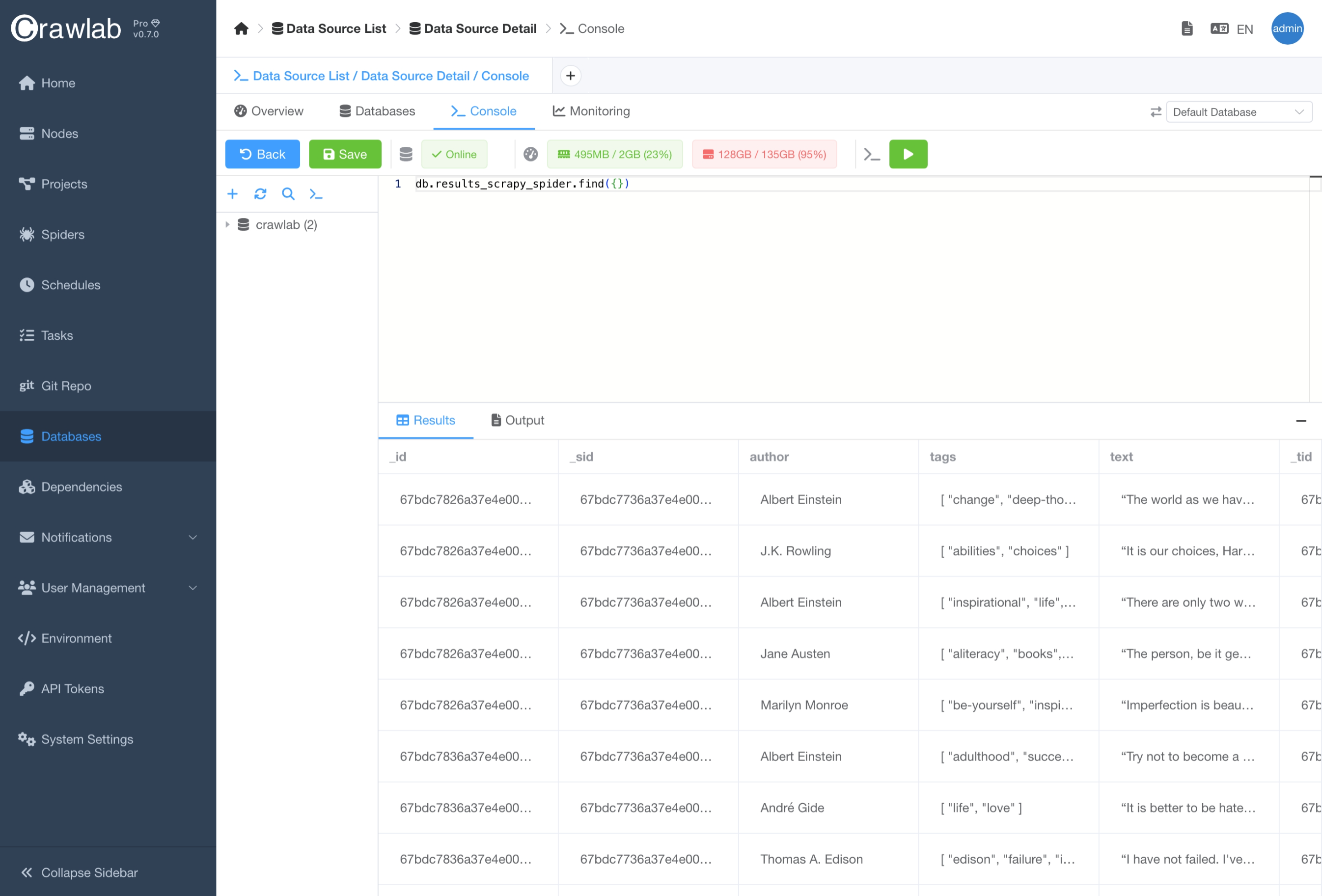
执行查询
您还可以在 数据库 详细页面的 控制台 标签页中执行数据库查询。当您想在代码中运行查询之前测试它们时,这非常有用。
ORM 模式
从 v0.7.0 开始,Crawlab 为 SQL 数据库提供原生 ORM(对象关系映射) 支持,由 GORM 驱动。
启用 ORM 模式后,Crawlab 会自动管理你的数据库表结构并执行类型安全的操作,包括自动的表结构检测与表管理——
因此在存储抓取数据前,你不再需要手动编写 CREATE TABLE 语句。
支持的数据库
ORM 模式适用于以下数据源:
- MySQL
- PostgreSQL
- SQL Server
其他数据源(如 MongoDB、Elasticsearch)继续使用 Crawlab 的原生存储处理,不会显示 ORM 开关。
启用 ORM
对于受支持的数据库,数据库设置中会显示一个 ORM 开关。开启后即为该数据库启用由 ORM 管理的表结构与写入; 关闭后则恢复为旧版存储服务。该设置是按数据库生效的,因此你可以选择性启用。
创建数据库时,Crawlab 会初始化一个合理的默认值——对受支持的数据源默认启用 ORM,其余则默认关闭。 你可以随时更改;该开关是非破坏性的,不会删除已有数据。
ORM 模式仅影响 Crawlab 如何管理所选数据库的表结构与写入。切换时会保留已有数据,因此你可以增量迁移。
ORM API
ORM 状态也可以通过 REST API 进行管理:
| 方法与路径 | 说明 |
|---|---|
GET /databases/{id}/orm/status | 数据库的 ORM 是否 enabled(已启用)及是否 supported(受支持) |
PUT /databases/{id}/orm/status | 启用或关闭 ORM({"enabled": true}) |
GET /databases/{id}/orm/compatibility | 兼容性详情,包括原因及 ORM 支持的数据源列表 |
POST /databases/{id}/orm/initialize | 应用该数据库数据源的默认 ORM 设置 |
完整的请求与响应结构请参阅 API 参考中的 ORM 状态 API 及相关端点。
连接到数据库
在 数据集成 部分,您已经学习了如何使用 Crawlab SDK 将数据存储到 Crawlab 以便预览抓取的数据。
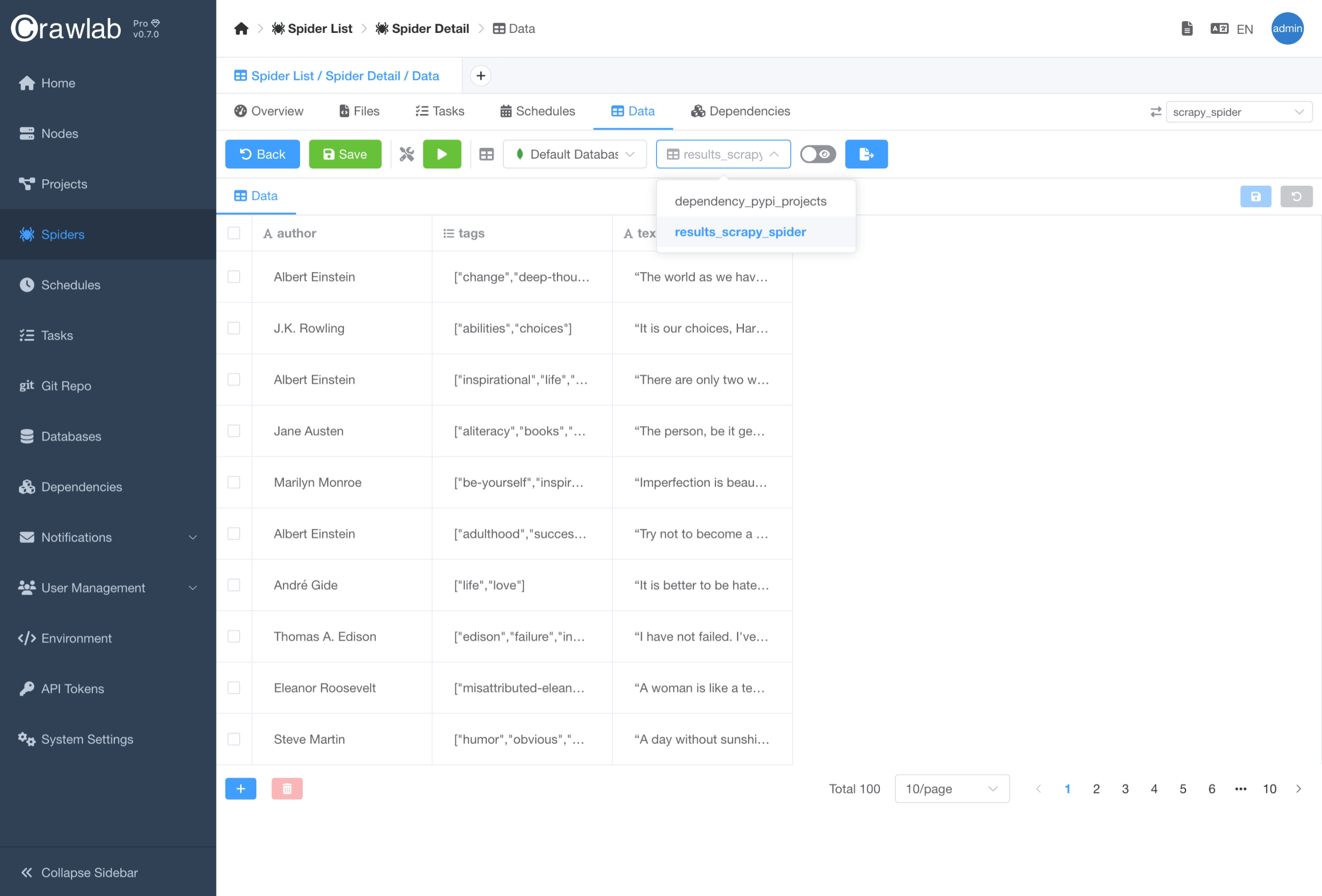
数据库模块旨在成为集中式数据库管理界面,您可以在此轻松管理您的数据库和表。此外,您可以在 爬虫 详细页面中选择要存储抓取数据的数据库。
按照以下步骤连接到数据库。
- 在
数据库列表页面中创建一个新数据库。 - 导航到
爬虫详细页面。 - 导航到
数据标签页。 - 选择要存储抓取数据的数据库和表。