数据源
数据源
Crawlab 支持数据源集成,这意味着您可以使用 Crawlab 管理您的数据源,例如 MongoDB、MySQL、PostgreSQL、SQL Server 等。
支持的数据源
| 类别 | 数据源 | 支持 |
|---|---|---|
| 非关系型 | MongoDB | ✅ |
| 非关系型 | ElasticSearch | ✅ |
| 关系型 | MySQL | ✅ |
| 关系型 | PostgreSQL | ✅ |
| 关系型 | SQL Server | ✅ |
| 关系型 | CockroachDB | ✅ |
| 关系型 | Sqlite | ✅ |
| 流处理 | Kafka | ✅ |
新建数据源
- 导航至
数据源页面
- 点击
新建数据源按钮
- 选择
类型作为数据源类型,并输入名称以及连接信息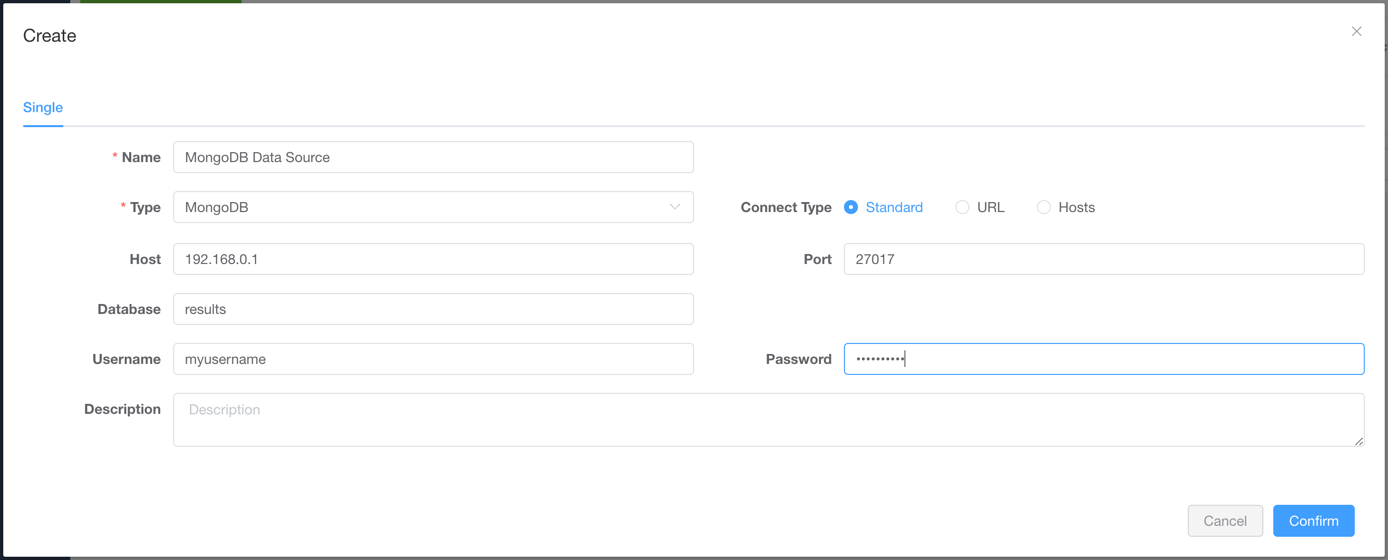
- 点击
保存按钮
使用数据源
- 导航至
爬虫详情页面 - 在
数据源中选择相应的数据源
- 点击
保存按钮 - 在保存结果数据的地方,添加相应的集成代码 (参考下面的
爬虫代码例子) - 运行爬虫,您将能在
数据标签中看到结果数据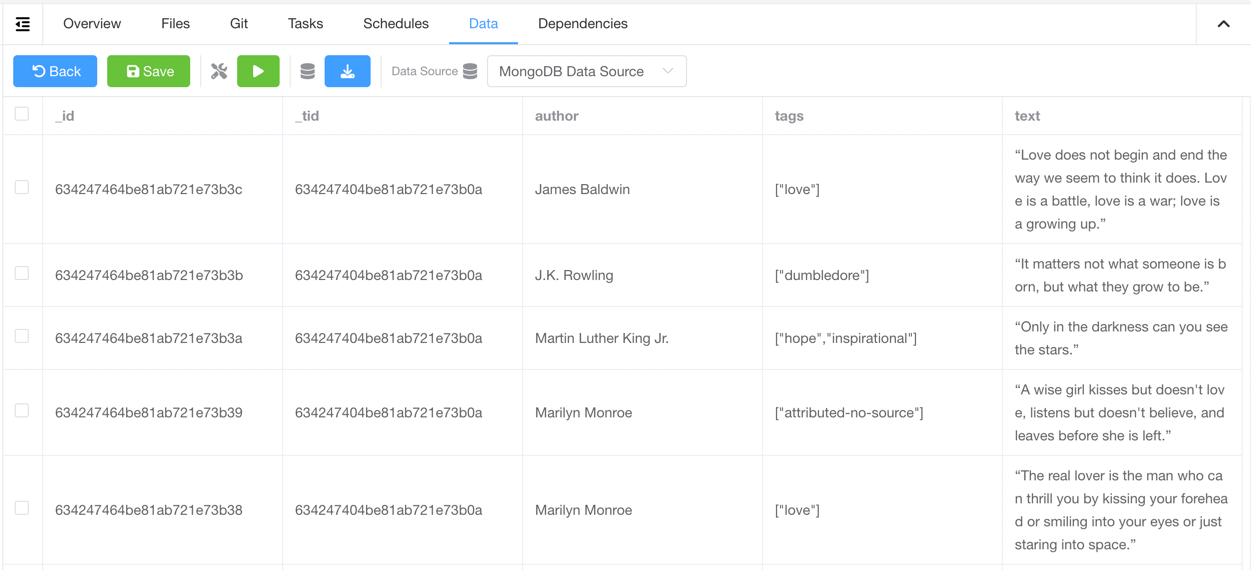
爬虫代码例子
通用 Python 爬虫
crawlab-sdk 的方法 save_item 可被调用来保存数据到对应的数据源。
```py
from crawlab import save_item
...
save_item(result_item)
...
Scrapy 爬虫
添加 crawlab.CrawlabPipeline 至 settings.py.
ITEM_PIPELINES = {
'crawlab.CrawlabPipeline': 300,
}