Data Sources
Data Sources
Crawlab supports data sources integration, which means you can use Crawlab to manage your data sources, such as MongoDB, MySQL, PostgreSQL, SQL Server, etc.
Supported Data Sources
| Category | Data Source | Supported |
|---|---|---|
| Non-Relational | MongoDB | ✅ |
| Non-Relational | ElasticSearch | ✅ |
| Relational | MySQL | ✅ |
| Relational | PostgreSQL | ✅ |
| Relational | SQL Server | ✅ |
| Relational | CockroachDB | ✅ |
| Relational | Sqlite | ✅ |
| Streaming | Kafka | ✅ |
Add Data Source
- Go to the
Data Sourcespage
- Click
New Data Sourcebutton
- Select
Typeas the data source type, and enterNameand connection fields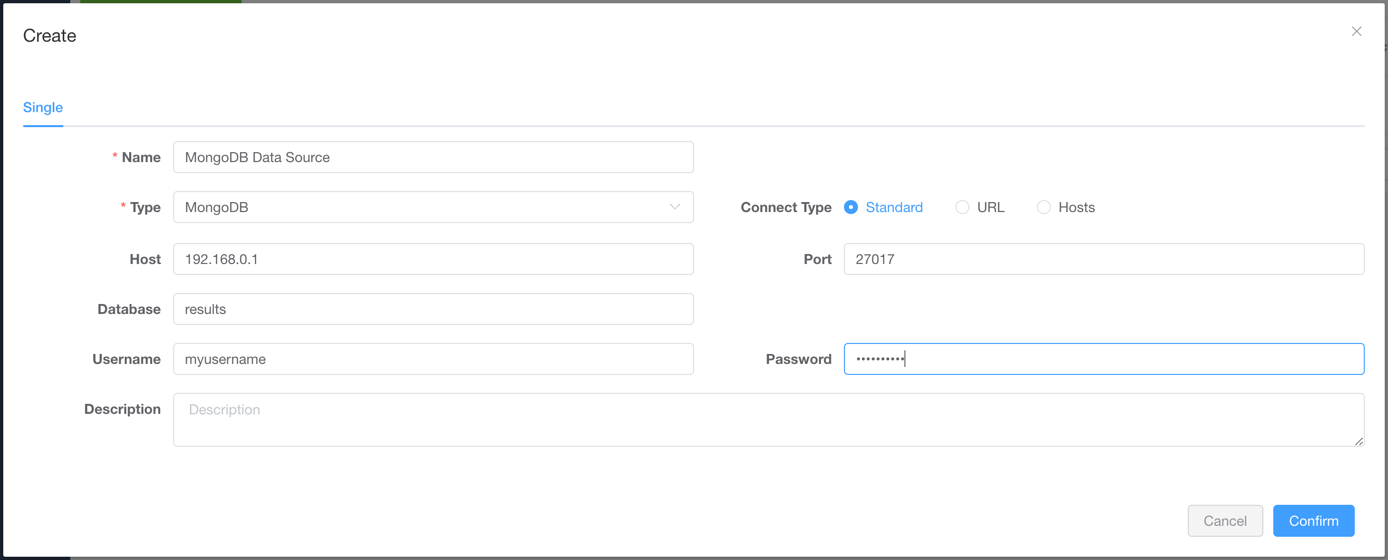
- Click
Confirmbutton to save the data source
Now you should be able to see the data source in the Data Sources page.
Use Data Source
- Go to the
Spider Detailpage - Select the data source in the
Data Sourcefield
- Click on
Savebutton to save the spider - Add related integration code in the code where saving results data (refer to the
Spider Code Examplessection below) - Run the spider, and you should see the results in the
Datatab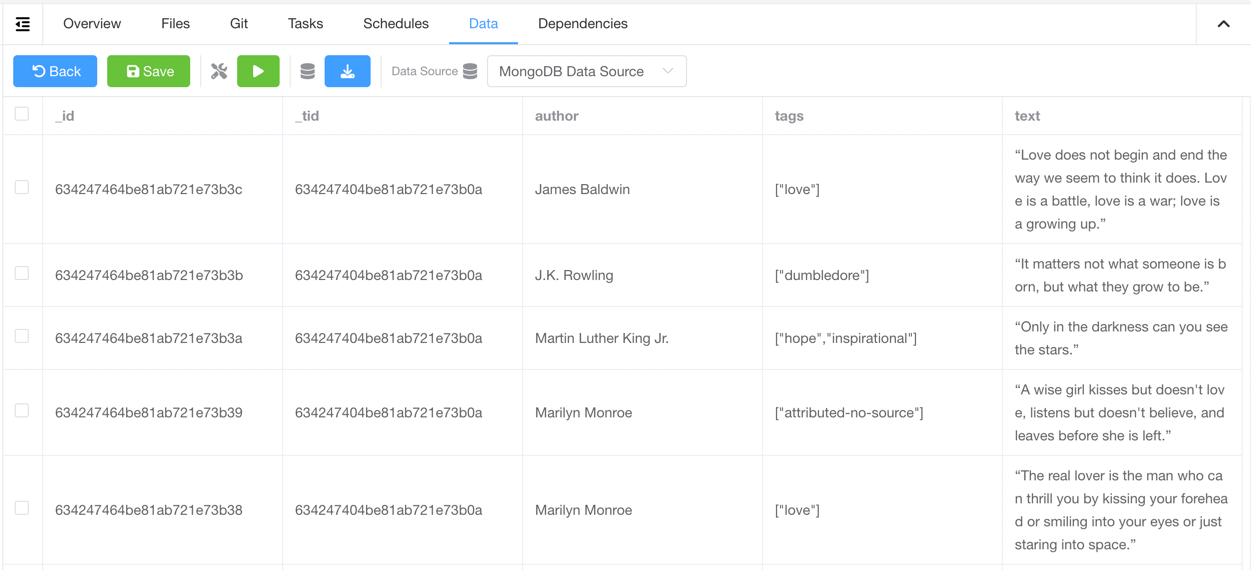
Spider Code Examples
General Python Spider
The method save_item in crawlab-sdk can be used to save data to designated data source.
```py
from crawlab import save_item
...
save_item(result_item)
...
Scrapy Spider
Add crawlab.CrawlabPipeline to settings.py.
ITEM_PIPELINES = {
'crawlab.CrawlabPipeline': 300,
}